这一系列博文我们对 Diffusion 模型进行简单的介绍 :)
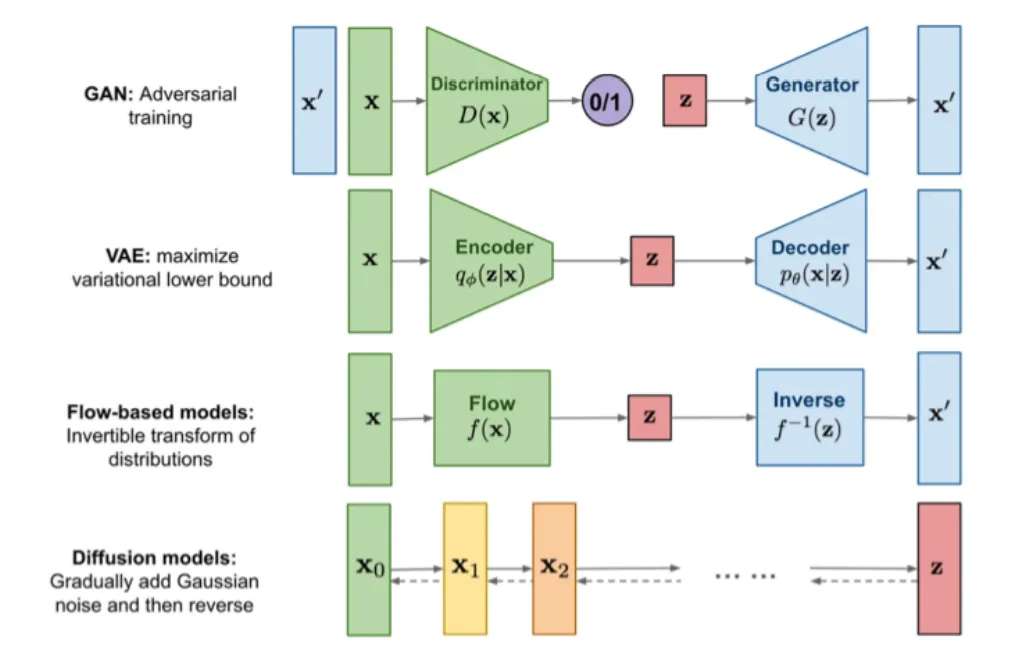
我们认为比较重要的 Paper List:
- 重新回顾 Diffusion:更具多样性的生成式模型
- [1503.03585] Deep Unsupervised Learning using Nonequilibrium Thermodynamics (ICML’15)
- [2006.11239] Denoising Diffusion Probabilistic Models (NIPS’20)
- [2102.09672] Improved Denoising Diffusion Probabilistic Models (ICML’21)
- [2010.02502] Denoising Diffusion Implicit Models (ICLR’21)
- [2106.15282] Cascaded Diffusion Models for High Fidelity Image Generation (JMLR)
- [2104.07636] Image Super-Resolution via Iterative Refinement (TPAMI)
- 为生成添加引导
- [2105.05233] Diffusion Models Beat GANs on Image Synthesis (NIPS’21)
- [2112.10741] GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models (ICML’22)
- [2207.12598] Classifier-Free Diffusion Guidance (NIPS’21 Workshop)
- Departure to Latent Space
- [2112.10752] High-resolution image synthesis with latent diffusion models (CVPR’22 Oral)
- [2302.05543] Adding Conditional Control to Text-to-Image Diffusion Models
- [2204.06125] Hierarchical Text-Conditional Image Generation with CLIP Latents (DALL·E 2)
- [2205.11487] Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (NIPS’22, Imagen)
- 未分类(还没读,咕咕咕)
- Zero-Shot Contrastive Loss for Text-Guided Diffusion Image Style Transfer
DDPM
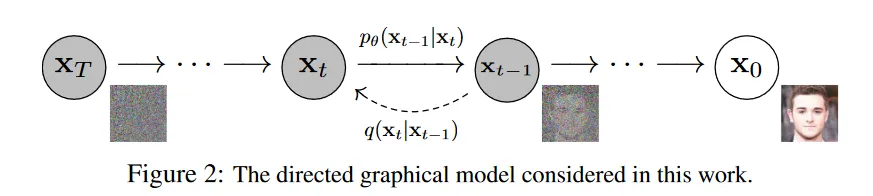
DDPM(Denoising Diffusion Probabilistic Models)是一种生成式模型,其可以将噪声 xT 经过一系列级联的去噪(Denoising)过程生成具有真实感的图像 x0。
在 DDPM 中,具有两个重要的过程:前向过程(forward process, or diffusion process)和去噪过程(denoising process):
前向过程
前向过程,也就是图中的 q 过程,通过不断加高斯噪音的方式将原始数据分布 q(x0) 转换为简单易处理的标准正态分布。在前向过程中,一个初始的噪声图像 xT 被迭代地与一系列高斯噪声进行混合,生成一系列经过随机扰动的图像 xt,其中 t=T−1,T−2,…,0。
更加形式化地,我们可以表示为:
q(xt∣xt−1):=N(xt;1−βtxt−1,βtI)
这里 q(xt∣xt−1) 表示隐变量 xt 相对于 xt−1 的条件概率分布。也就是说,如果我们已知隐变量 xt−1 的取值,想要获得隐变量 xt 的取值,我们就要从这个关于 xt 的正态分布中采样,其均值为 1−βtxt−1,方差为 βtI。这里的数列 βt 由人工手动定义,在原文的实现中实现为在 β1=10−4 到 βT=0.02 的线性插值,这里 T=1000。直观上,每一步前向过程的操作就是对输入的数据加入高斯噪声的扰动。
在该算法中,从原始图片输入 x0 到完全的高斯噪声 xT 的过程是由一系列 q 过程级联产生的。我们认为这个级联后的过程是一个马尔科夫过程,这意味着在任意时间 t,当前状态 xt 的条件概率分布只依赖于其前一个状态 xt−1,即:
q(xt∣xt−1,xt−2,…,x0)=q(xt∣xt−1)
这里 q(xt∣xt−1,xt−2,…,x0) 表示在给定之前的所有状态的条件下,当前状态 xt 的条件概率分布,q(xt∣xt−1) 表示当前状态 xt 相对于 xt−1 的条件概率分布。根据马尔科夫过程的性质,我们有:
q(x1,x2,⋯,xT∣x0)=t=1∏Tq(xt∣xt−1)
这里 q(x1,x2,⋯,xT∣x0) 表示隐变量 x1,x2,⋯,xT(之后简记为 x1:T)相对于 x0 的联合条件概率分布。
同时,根据高斯分布的可叠加性,我们可以得出:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I),
这里 αt:=1−βt, αˉt:=∏s=1tαs。
去噪过程
我们希望去噪过程是上述前向过程的逆过程,也就是说,我们要获得 q(xt∣xt−1) 的逆分布。我们知道,如果 q(xt∣xt−1) 是正态分布且 βt 足够接近 0,那么其逆过程也近似为一个正态分布。我们通过一个神经网络 θ 来拟合这个正态分布的均值(与方差,Improved DDPM)。
pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))
如果这个网络 θ 被成功训练到可以拟合 p 过程,那么我们就具有了一个具有“去噪”能力的网络。进而,我们可以从标准正态分布中采样 xT,然后经过 T 次 pθ 的变换,便得到了具有真实感的图像 x0。
马尔可夫过程保证了:
pθ(x0:T):=p(xT)t=1∏Tpθ(xt−1∣xt)
训练过程
训练的目标是通过模型生成的数据分布 pθ(x0) 与真实数据分布 q(x0) 尽可能相近。这可以通过最小化假设检验 E[−logpθ(x0)] 来实现。由于:
pθ(x0)pθ(x0:T)=∫pθ(x0:T)dx1:T=pθ(xT)t=1∏Tpθ(xt−1∣xt)
我们尝试去推出 E[−logpθ(x0)] 的上界,通过将其上界优化小的方式去优化该假设检验值:
Lce=−Eq(x0)(logpθ(x0))=−Eq(x0)(log∫pθ(x0:T)dx1:T)=−Eq(x0)(log∫q(x1:T∣x0)q(x1:T∣x0)pθ(x0:T)dx1:T)=−Eq(x0)(logEq(x1:T∣x0)(q(x1:T∣x0)pθ(x0:T)))≤−Eq(x0)(Eq(x1:T∣∣x0)(logq(x1:T∣x0)pθ(x0:T)))=−∬q(x0)q(x1:T∣x0)logq(x1:T∣x0)pθ(x0:T)dx0dx1:T=−∫q(x0:T)logq(x1:T∣x0)pθ(x0:T)dx0:T=−Eq(x0:T)[logq(x1:T∣x0)pθ(x0:T)]=Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)]
这里用了变分自编码器(VAE)中的重要不等式,通常称为“ELBO(evidence lower bound)不等式”。下面对式子进行解释:
左边的期望值是关于潜在变量 z 的先验分布 p(z) 取期望后的结果,其中 z 通过生成模型 pθ(x0,z) 与观测变量 x0 相关联。根据贝叶斯定理,我们有:
pθ(x0,z)=pθ(x0∣z)p(z)
因此,可以将左边的期望值写成以下形式:
E[−logpθ(x0)]=Ep(z)[−logpθ(x0∣z)]−H[p(z)]
其中,H[p(z)] 是潜在变量的先验分布 p(z) 的熵,可以看作是潜在变量的不确定度的度量。在我们的例子中,潜在变量 z 为 x1:T。
接下来我们用马尔科夫过程的性质把 Eq(x0:T)[logpθ(x0:T)q(x1:T∣x0)] 中的联合概率分布拆开。同时,因为 q(xt∣xt−1) 的分布的 closed-form solution 不可知,我们引入 x0 后利用贝叶斯公式可以转换成 q(xt−1∣xt,x0),这个分布的参数为:
q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)whereμ~t(xt,x0):=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xtandβ~t:=1−αˉt1−αˉt−1βt
最终我们发现上述上界等价于:
Eq[LTDKL(q(xT∣x0)∥p(xT))+t>1∑Lt−1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0−logpθ(x0∣x1)]
我们希望的优化目标,便是这些概率分布之间的 KL 散度。
优化目标的进一步改进
我们考虑 Lt−1,由于计算 KL 散度的两个分布都是正态分布,我们可以直接得到闭式解:
Lt−1=Eq(x0,xt)[2σt21∥μ~(xt,x0)−μθ(xt,t)∥2]+C
这相当于直接预测 pθ 过程的均值。
而由于我们在训练过程中知道前向过程 xt=αˉtx0+1−αˉtϵ,且在训练过程中要将 μθ(xt,t) 回归到的值只与 x0 和 xt 有关,于是我们可以代入消去这个回归值中的 x0,得到我们要把 μθ(xt,t) 回归到:
αt1(xt−1−αˉtβtϵ)
而这里的 xt 是 μθ(xt,t) 的输入。本着简便的原则,我们可以设计:
μθ(xt,t)=αt1(xt−1−αˉtβtϵθ(xt,t))
也就是说,我们的网络 ϵθ 最终只需要输入 xt 和当前时间的 time embedding,输出我们在前向过程中相对原图添加的噪声即可。
于是我们可以对 Loss 稍作修改:
Ex0,ϵ[2σt2αt(1−αˉt)βt2ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)2]
再简便一些,我们丢弃前面的系数:
Lsimple (θ):=Et,x0,ϵ[ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)2]
这相当于对于不同时间步的 Loss 做了一个分配不同权重的操作。事实上,这里将 t 较小的时间步的 Loss 权重降低,使得模型不用花费太多精力在考虑 fine-grained 的细节上。
Reference
除了原论文外,本节内容的整理我们参考了以下内容:
感觉水够一篇的篇幅了,换一篇接着写 :)